Apache Ranger Evaluation for Cloud Migration and Adoption Readiness

Apache Ranger is an open-source authorization solution that provides access control and audit capabilities for Apache Hadoop and related big data environments. It is an integral part of on-prem Hadoop installations, commercial solutions like Cloudera Data Platform, cloud managed Hadoop offerings like Amazon EMR, GCP Cloud Dataproc, or Azure HDInsight.
The plugin-based architecture enables support for Hive, HBase, Kafka, Impala, Kylin, NiFi, Spark, Presto, etc. Also, the plugin method allows Ranger beyond the Hadoop ecosystem, for example secure AWS S3 objects. Yet, there are no open source connectors for modern data platforms like Databricks, Snowflake, BigQuery, Azure Synapse, or Redshift.
I have taken an interest in data governance for engineers and have observed a lot of disruption to data access when migrating from hadoop platforms to modern cloud data architectures such as Databricks, Synapse or Snowflake. The data access patterns have become more complex as the cloud unlocks more use cases and workloads.
Ranger is an open source project by Hortonworks for the Hadoop ecosystem created back in 2014 that provides policy management around accessing a resource (file, folder, database, table, column etc.) for a particular set of users and/or groups. To contrast impacts of data access governance in the cloud, I created a set of policy scenarios from use cases and acceptance criteria collected and generalized from cloud expansion projects with sensitive data environments. This article explores different access scenarios and showcases implementation steps in Apache Ranger to understand the impacts on this project from cloud adoption readiness.
About evaluation
Policy scenarios use the TPC-DS dataset. TPC-DS models the decision support functions of a retail product supplier. The supporting schema contains vital business information, such as customer, order, and product data that is intended to mimic much of the complexity of a real retail data warehouse.
About the data and scenarios
The TPC-DS schema models the sales and sales returns process for an organization that employs three primary sales channels: stores, catalogs, and the Internet. The schema includes seven fact tables:
- A pair of fact tables focused on the product sales and returns for each of the three channels
- A single fact table that models inventory for the catalog and internet sales channels
In addition, the schema includes 17 dimension tables that are associated with all sales channels.
The TPC-DS is created and maintained by the Transaction Processing Performance Council. More details may be found at tpc.org.
My objective is to show policy maintenance as a measure of scale. For each scenario, I count the following aspects:
- Policies created
- Policies edited
- User attributes created
- User attributes edited
- Tag created
- Tag applied
Environment setup
Acquire an EC2 instance via Amazon via https://portal.aws.amazon.com/
Select Installation Type: Docker - Follow the instructions to install Docker on the EC2 instance
Deploy HDP to Docker container
Result summary
| Other Policy Scenarios | Result |
|---|---|
| 3a - Grant permission based on AND Logic | Unable to create policy |
| 3b - Minimization Policies | Unable to create policy |
| 3c - De-identification | Unable to create policy |
| 3d - Policies with Purpose | Unable to create policy |
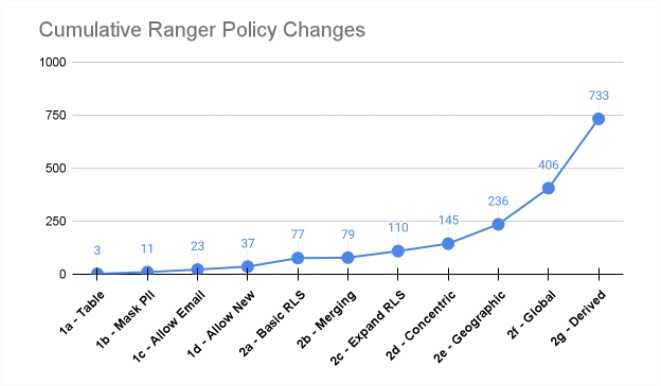
The number of cumulative policy changes climbing to 733 for the scenarios reflective of cloud adoption were higher than I expected for the first 11 policy scenarios, and a number of scenarios were not possible which will limit data access for those requirements.
From my perspective, the number of policy changes is dangerously high and imposes following risks:
1. Misconfiguration
According to the latest Verizon’s 2021 Data Breach Investigations Report, misconfiguration is one of the top threats, often accounted for over 70% of all security errors. The high number of Ranger policy changes leaves too much space for misconfigurations and human error.
2. Time and effort needed
Policy changes, collecting approvals, policy validation, periodic reviews is a time consuming task, which might become a bottleneck for companies with a high number of data assets and/or complex organizational structure.
3. Engineers (de)motivation
Jeff Magnusson wrote a brilliant piece on why Engineers Shouldn’t Write ETL. I agree with the author that everybody wants to be the “thinker”, deliver business value. I haven’t yet met an engineer who would enjoy working on access policy changes.
4. The fear of saying “no” to the business
4 of the 15 policy scenarios were not possible to implement in Ranger. Clever engineers will always find ways to overcome solution limitations, and there are ways “to hack” Ranger to meet all the requirements. However, it has to be a conscious decision on what type of customization is allowed for an enterprise security and access management, how one validates and certifies it afterwards.

Detailed Summary of Evaluation
Table of Contents
Table Access and Column Masking
- Scenario 1a: Provide access to all data for central office employees
- Scenario 1b: Mask all data labeled PII
- Scenario 1c: Allow email domains through masking policy
- Scenario 1d: Allow an additional two users access to all PII data
Row-Level Security
- Scenario 2a: Basic Row-Level Security
- Scenario 2b: Merging Groups
- Scenario 2c: Apply the same RLS policy to two more tables
- Scenario 2d: Concentric Row-Level Security
- Scenario 2e: Employees may only view customers in their country
- Scenario 2f: Users on the data and analytics team should have access to all records by default
- Scenario 2g: Re-creating policies on derived datasets
Advanced Access Controls and Privacy
- Scenario 3a: Grant permission based on “AND” logic
- Scenario 3b: Minimization Policies
- Scenario 3c: De-identification Policies
- Scenario 3d: Policies with Purpose Restrictions
The future of data access management
Table Access and Column Masking
Scenario 1a: Provide access to all data for central office employees
Background:
The central Total Protection Co. data science team has just created their new retail data warehouse mart and entitled the TPC-DS. Now it’s time to start getting it in the hand of employees across the company.
Data:
24 tables from the TPC-DS dataset
Users:
All users are in the existing Active Directory group:
- AD group: central-office
Requirements:
- All users in the central-office may “select” from all tables.
Steps in Ranger:
- Create a new access policy, Central office policy, to grant access to all 24 tables in tpcds database.
- Specify the database, tables (*), columns (*), and allow conditions (select, for central-office).
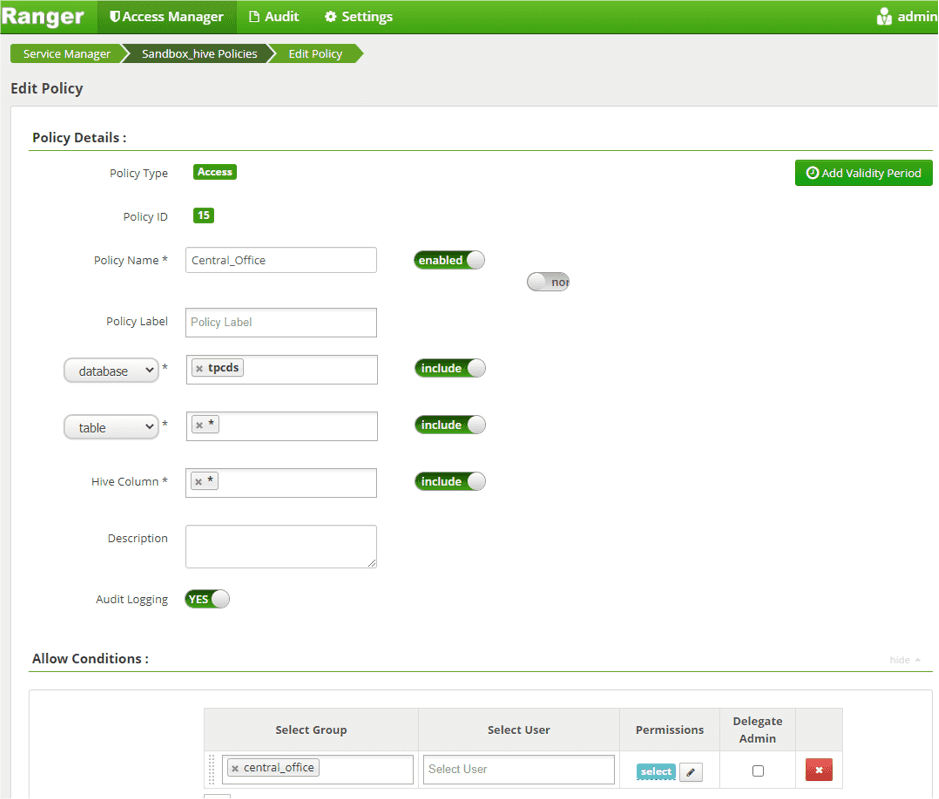
Scenario 1b: Mask all data labeled PII
Background:
As good stewards of their data, the team wants to mask any data across all tables that is classified as Personal Identifying Information by an automated service.
Only individuals who have been manually approved by the admin team should be able to access PII data.
Data:
All tables that contain PII. According to Google’s Data Loss Prevention service, this includes customer, call_center tables.
Requirements:
All data suspected to be PII should be made null.
Users:
Users with override permission are manually approved and do not have an group.
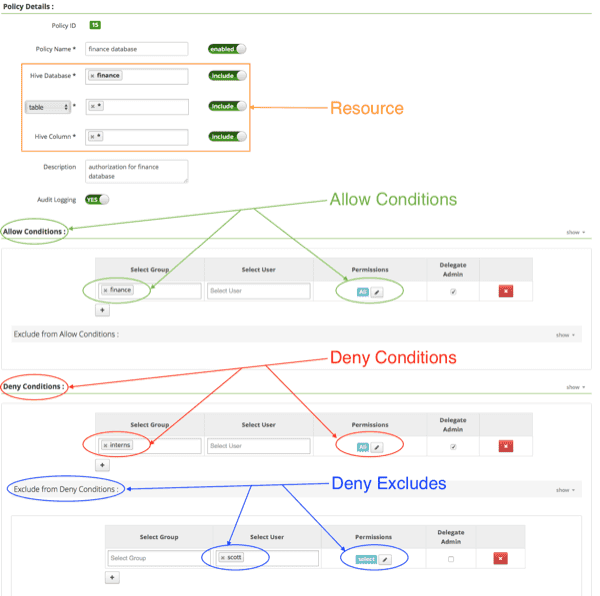
Steps in Ranger:
- Synchronize a PII tag from an external service.
Apache Ranger can synchronize tags from an external service, such as Apache Atlas, but does not have built-in data discovery. Read more.
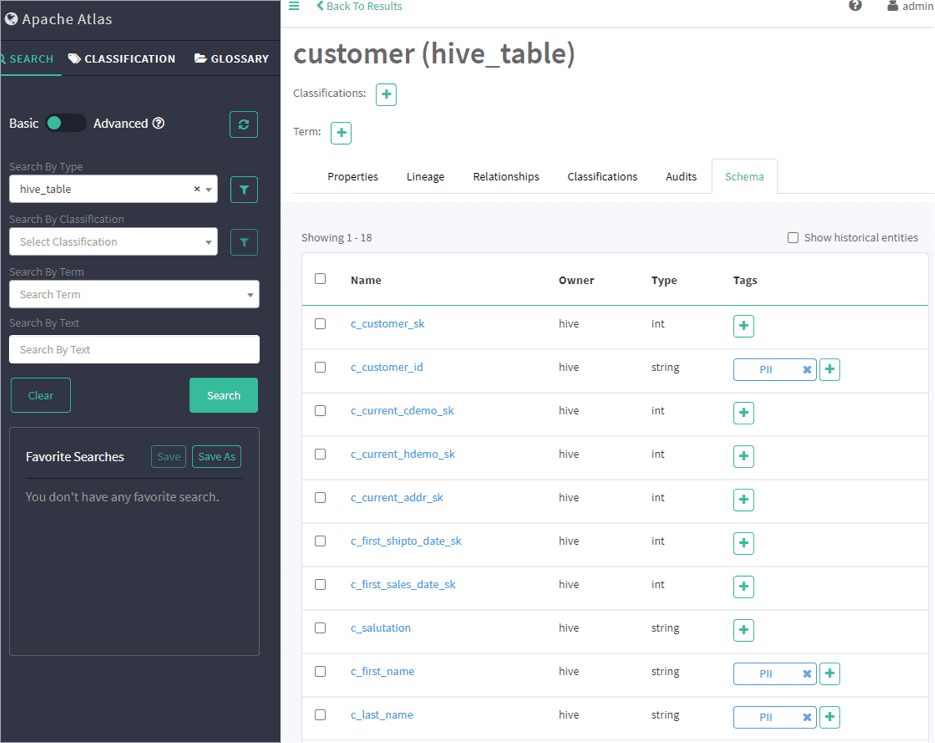
- Create Tag Based Policies service in Ranger
- Link Tag Based Service to Resource Based Service
- Create a new Policy to Allow Access PII data
- Add an Allow condition for authorized users.
- Add a Deny condition for “public”
- Add a Deny exception for authorized users.
- Add a new policy.
- Create a new Policy to Mask PII data
- Add a masking option to retain original value for authorized users
- Add a masking option to nullify values for “public”
- Add a new policy.
Comments:
Because no group exists, the Ranger policy must hardcode the exempted users from the PII requirement. A recommended option would be to create a dedicated group for users with PII access.
Scenario 1c: Allow email domains through masking policy
Background:
After reviewing the policy, the team has decided some information would be valuable to allow through the masking policy.
Data:
All tables that contain an email address. There are 2 instances of this in the TPC-DS tables: customer and promotion tables.
Users:
The same logic as prior scenarios should be applied.
Requirements:
Authorized users should be able to see email domains only, without the username.
Steps in Ranger:
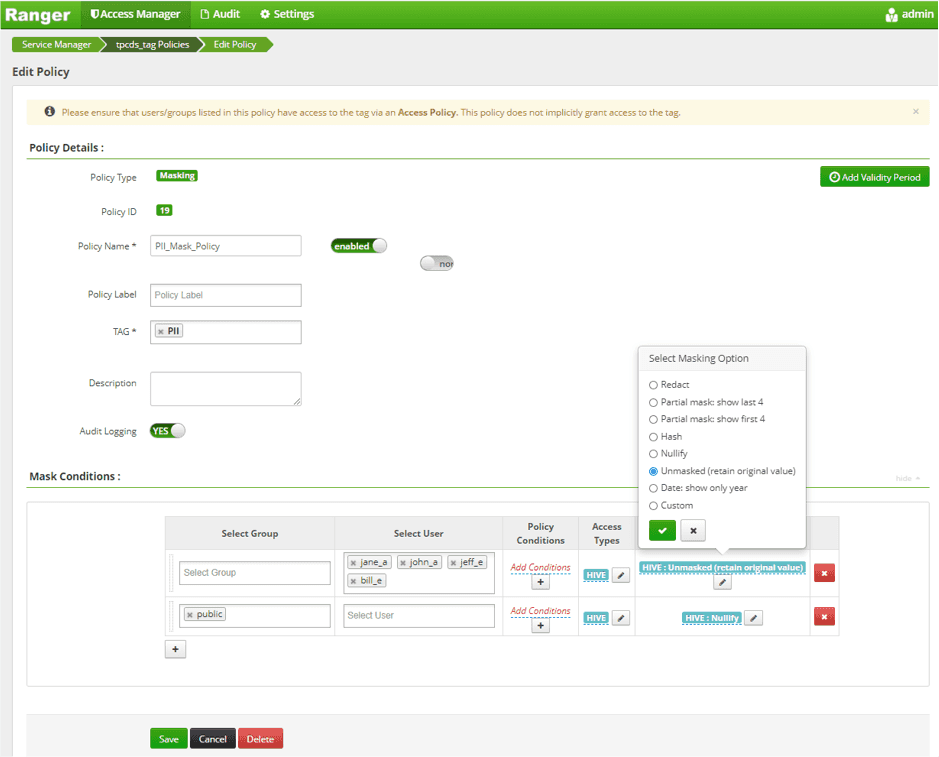
- Synchronize an EMAIL tag from an external service (see above)
- Follow the steps in Scenario 1b to create two new masking policies (access and masking policies for EMAIL)
- Ranger does not have a regular expression masking policy, but may extract the last 4 characters from the string.
- Add the appropriate exceptions for individual users.
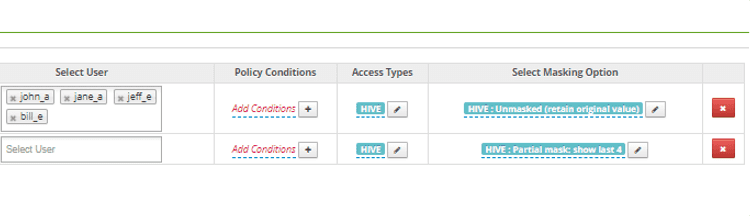
Comments:
Ranger does not allow nesting of columns and instead relies on the “ordering” of policy rules.
Scenario 1d: Allow an additional two users access to all PII data
Background:
Two new users have been assigned to the team and need to be authorized to access all PII data.
Data:
Tpcds database tables with PII.
Users:
The users are not part of an AD group that contains them.
Requirements:
Two new users should be able to see all PII data and email domains only, without the username.
Steps in Ranger:
- Add the two new users to policies created earlier:
- Central office policy to access all tpcds database tables
- PII & EMAIL access policies
- PII & EMAIL masking policies
Comments:
For each of the masking policies created, add the users to the “Allow” and “Exclude from Deny” condition selection box. A recommended option would be to create a dedicated group for users with PII access.
Scenario 1a - 1d: Total Counts of Policies Created/Edited, User Attributes Created/Edited, and Tag Created/Edited of each scenario
| Scenario | 1a | 1b | 1c | 1d |
|---|---|---|---|---|
| Policies created | 1 | 2 | 2 | 0 |
| Policies edited | 1 | 0 | 1 | 5 |
| User attributes created | 1 | 4 | 4 | 0 |
| User attributes edited | 0 | 0 | 2 | 7 |
| Tags created | 0 | 1 | 1 | 0 |
| Tags applied | 0 | 1 | 2 | 2 |
Row-Level Security
Scenario 2a: Basic Row-Level Security
Background:
A retailer wants to share a dataset of store performance, broken out by store. However, they do not want store managers to see the performance of their peers.
Data:
- store_sales table: Each row in this table represents a single line item for a sale made through the store channel and recorded in the store_sales fact table.
- Relevant column is: ss_store_sk (secondary key for store dimension table)
Users:
Each group has an existing Active Directory group:
- AD group: store-manager OR central-office
- AD group: store-id
Requirements:
- All 12 store managers may access their store sales.
- All central office personnel may access all sales.
Steps in Ranger:
- Write the Ranger policy based on user groups.
- Select the database and table for the policy
- Enter row-level conditions. For each AD group / store:
| group | access | condition |
|---|---|---|
| store-1 | select | ss_store_sk = <store_1_sk> |
| store-2 | select | ss_store_sk = <store_2_sk> |
| store-3 | select | ss_store_sk = <store_3_sk> |
| … + 9 | ||
| central-office | select | < no conditions > |
Create an Access Policy to Allow 12 Store Groups to Access tpcds database:
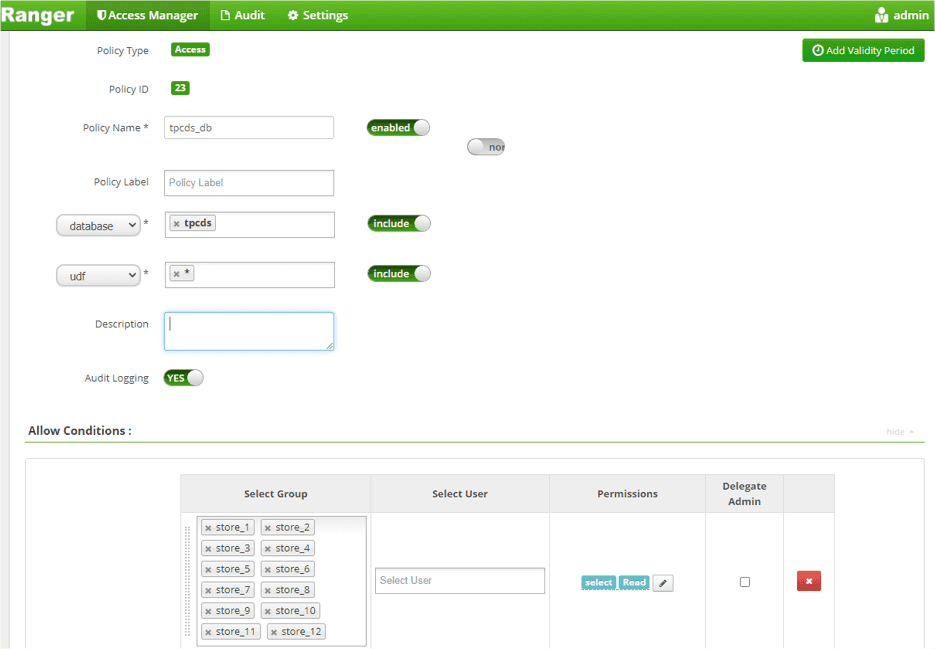
Create an Access Policy to Allow 12 Store Groups to Access store_sales tables:
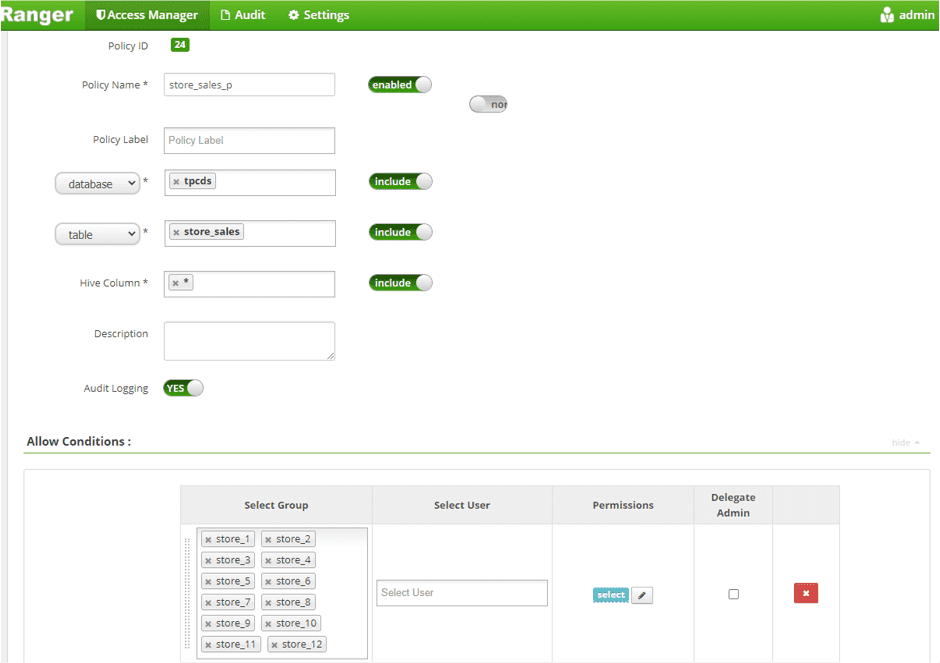
Create a Row Level Filter Policy to Allow Each Store Group to Access to their store_sales table, respectively:
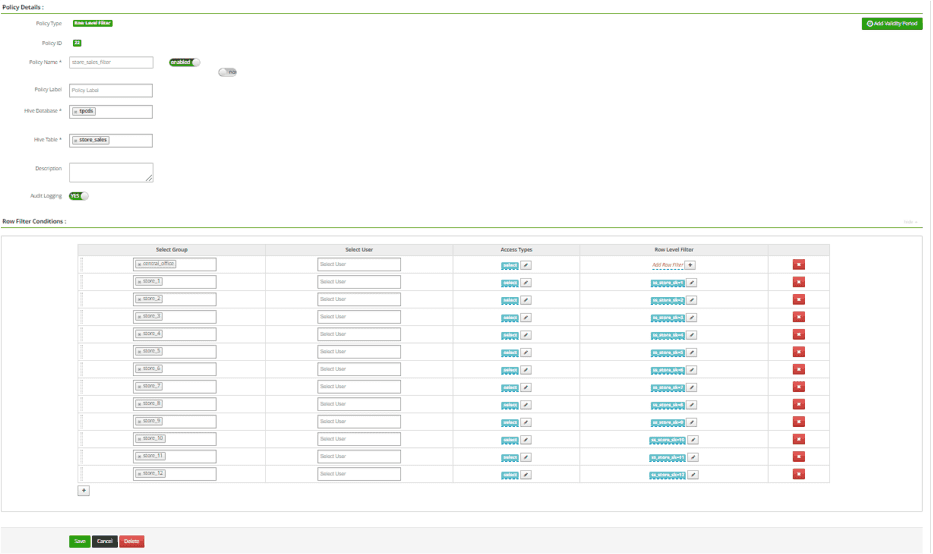
Comments:
It is required to “unpack” user groups, because the AD groups do not map exactly to the values registered in the database. In Ranger, the user needs to hardcode the mapping of an individual “group” to a “where clause”, resulting in a policy with 51 conditions (although potentially many more).
Scenario 2b: Merging Groups
Background:
A store manager has recently departed from the company, and her store will be managed by another store manager in the interim period.
Data:
Same data from Scenario 2a.
Users:
Same attributes from Scenario 2a.
Requirements:
In addition to the Scenario 2a requirements, the interim store manager should be able to see both the original and new region, without changing the dataset.
Steps in Ranger:
- Add the interim store manager from store-2 to store-1 AD Group
- Update the Row Level Filter Policy for the interim store manager
Comments:
The updated Row Level policy would also entitle the original store manager from store-1 to gain the access to the store-2 sales data.
Scenario 2c: Apply the same RLS policy to two more tables
Background:
The data team has added a second page to the store dashboard showing employee satisfaction. As in Scenario 2a, each manager should only have access to their store or region’s records.
Data:
Besides the “store_sales” table, we want to apply the same policy to all tables containing the “store_sk” key (have different column names).
- store_sales table: Described above.
- Relevant column is: ss_store_sk.
- store_returns table: Each row in this table represents a single line item for the return of an item sold through the store channel and recorded in the store_returns fact table.
- Relevant column is: sr_store_sk.
- store table: Each row in this dimension table represents details of a store.
- Relevant column is: s_store_sk.
Users
Same as prior policy scenario.
Requirements:
Requirements are identical to Scenarios 2a but applied to all 3 tables.
Steps in Ranger:
- Create new policies for the “store” and “store_returns” tables.
- Update the Access Policy to grant access to two new tables for 12 store AD groups as:
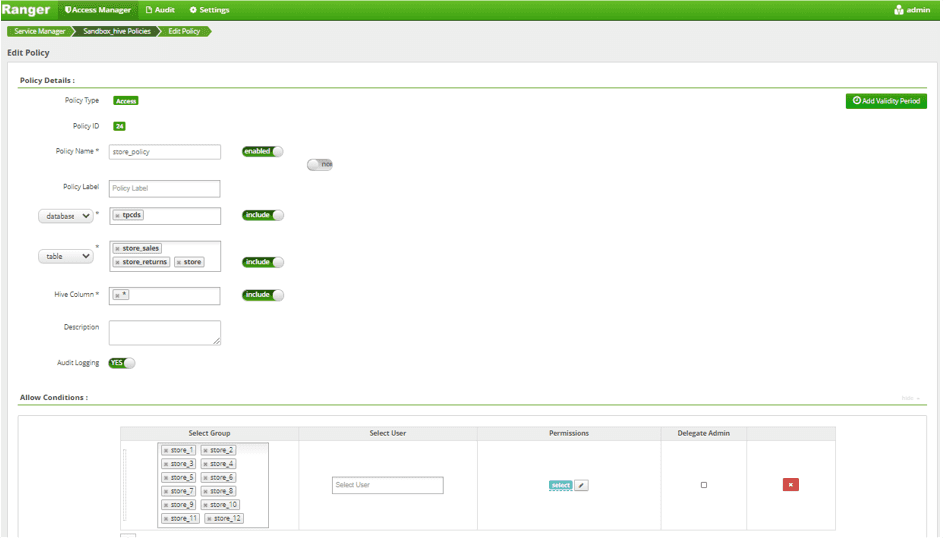
Comments:
You have to create new, separate policies for each table (not even duplicated, because the keyed-on column name changes).
Scenario 2d: Concentric Row-Level Security
Background:
The organization has decided to undergo an organizational restructuring, and they are adding in a new layer of “regional managers” with authorization into multiple stores.
Data:
Same as scenarios 2a-2c.
Users:
The organization has added another layer of groups, so that they now have.
- AD Group: store-manager OR region-manager OR central-office
- AD Group (Multiple): region-id
- AD Group (Multiple): store-id
Requirements:
- All 12 store managers may access their store sales, store_returns, and store metadata.
- All 6 regional managers may access their region’s sales, store_returns, and store metadata.
- All central office personnel may access all store sales, store returns, and store metadata.
Steps in Ranger:
- Add 10 row-level conditions to each of the three existing row-level policies.
| group | access | condition |
|---|---|---|
| region-1 | select | ss_store_sk in (<store_1_sk>, <store-2_sk>, …) |
| … + 5 more |
Update Access to tpcds Database Policy by adding 6 Region AD Group
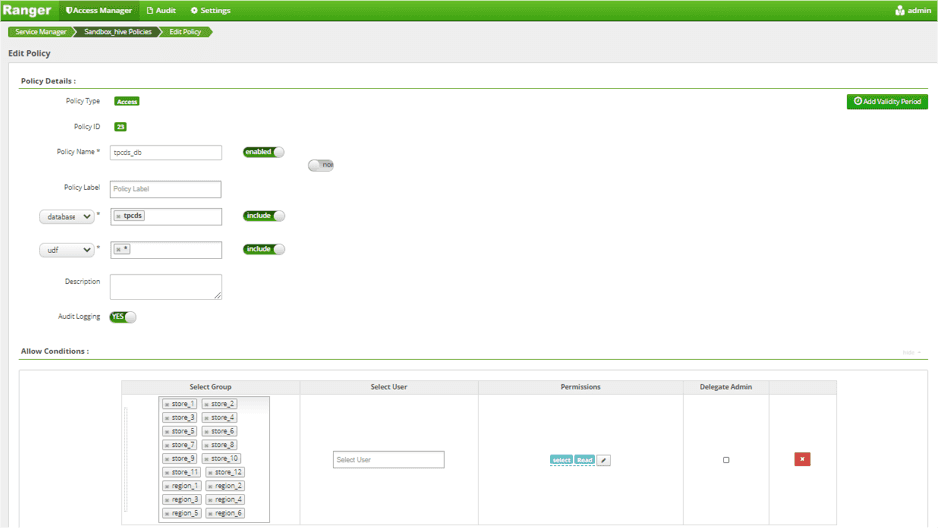
Update Access to 3 Store Tables Policies by adding 6 Region AD Group
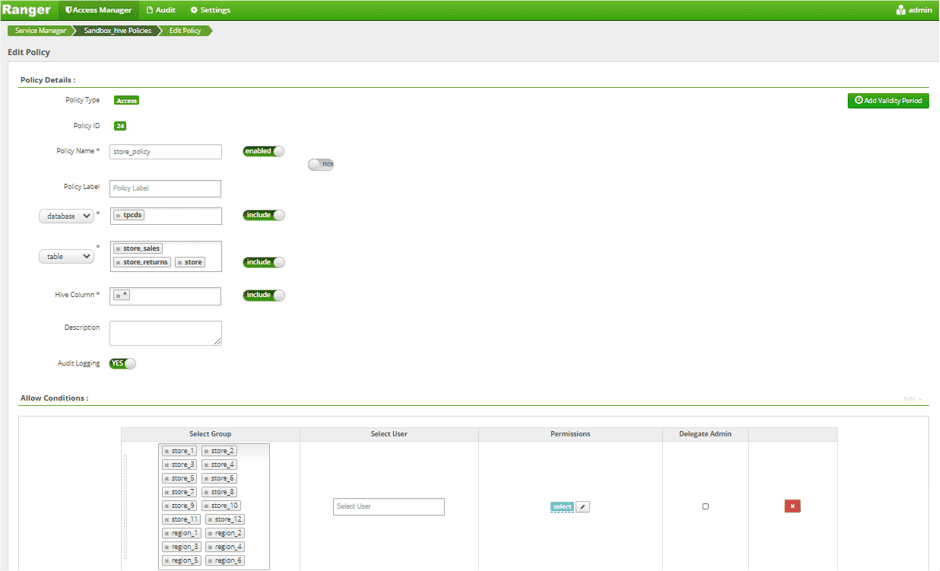
Update Store Sales Low Level Filter Policy by adding 6 Region AD Group
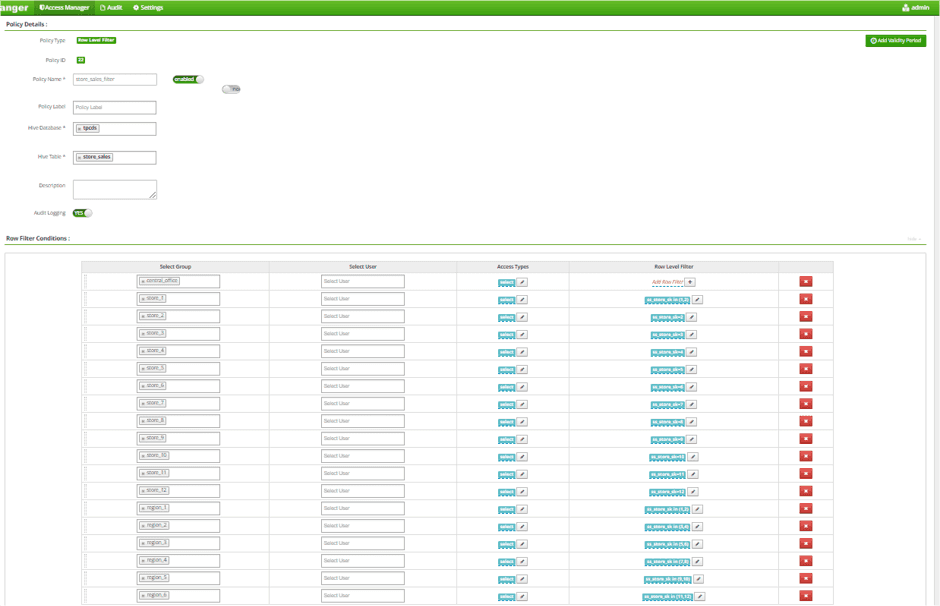
Update Store Returns Low Level Filter Policy by adding 6 Region AD Group
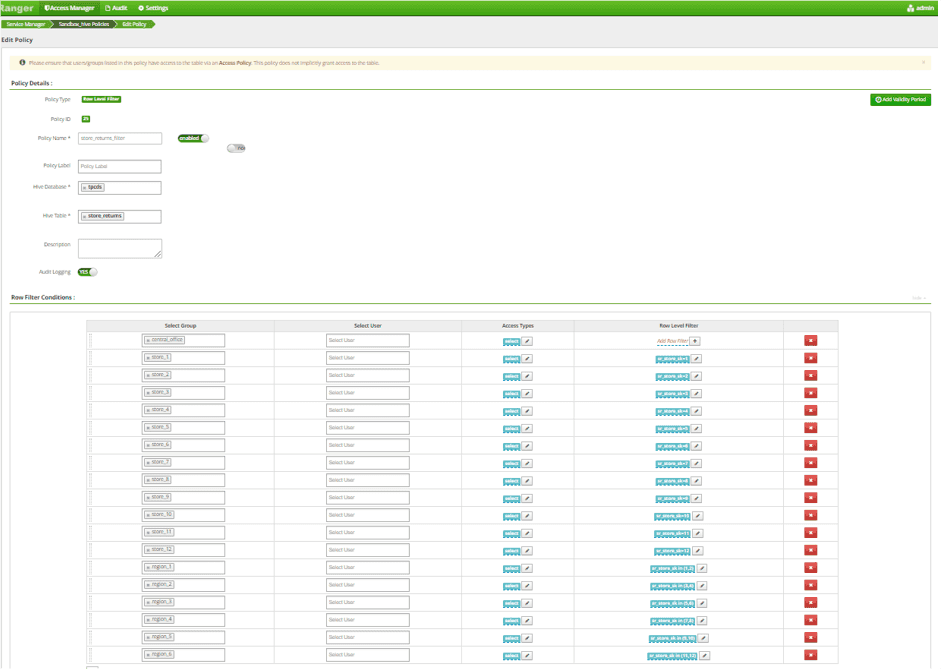
Update Store Metadata Low Level Filter Policy by adding 6 Region AD Group
Comments:
Once again, we are tripling the amount of policy work that needs to be done in Ranger by having to update multiple policies. We are also continuing to embed user authorizations into a SQL table, rather than manifesting them as user attributes in our policy management system, which reduces visibility into why a certain user may or may not have the appropriate access.
Scenario 2e: Employees may only view customers in their country
Background:
Your company has tripled in size and is expanding into new countries. A new internal policy has been passed that prohibits users from seeing record-level information on individuals in countries outside of their own country (unless explicitly authorized).
Data:
This new regulation applies to all tables in the schema that contain a customer reference. This includes six transaction fact tables and the customer dimension table:
- customer table:
- Customer country is identified by: c_birth_country
- Relevant columns: c_customer_sk
- catalog_returns table:
- Relevant columns: cr_refunded_customer_sk and cr_returning_customer_sk
- catalog_sales table:
- Relevant columns: cs_bill_customer_sk and cs_ship_customer_sk
- store_returns table:
- Relevant columns: sr_customer_sk
- store_sales table:
- Relevant columns: ss_customer_sk
- web_returns table:
- Relevant columns: wr_refunded_customer_sk and wr_returning_customer_sk
- web_sales table:
- Relevant columns: ws_bill_customer_sk and ws_ship_customer_sk
Users:
A new AD group has been added to individual users indicating their country.
- AD Group (Multiple): country-name
Requirements:
- All previous scenario requirements must be met.
- Central office personnel may access all country data.
Steps in Ranger:
The Ranger approach will require the creation of 7 new policies, each uniquely tailored to the column name(s) of the data source.
- Write the row-level policy against the customer table.
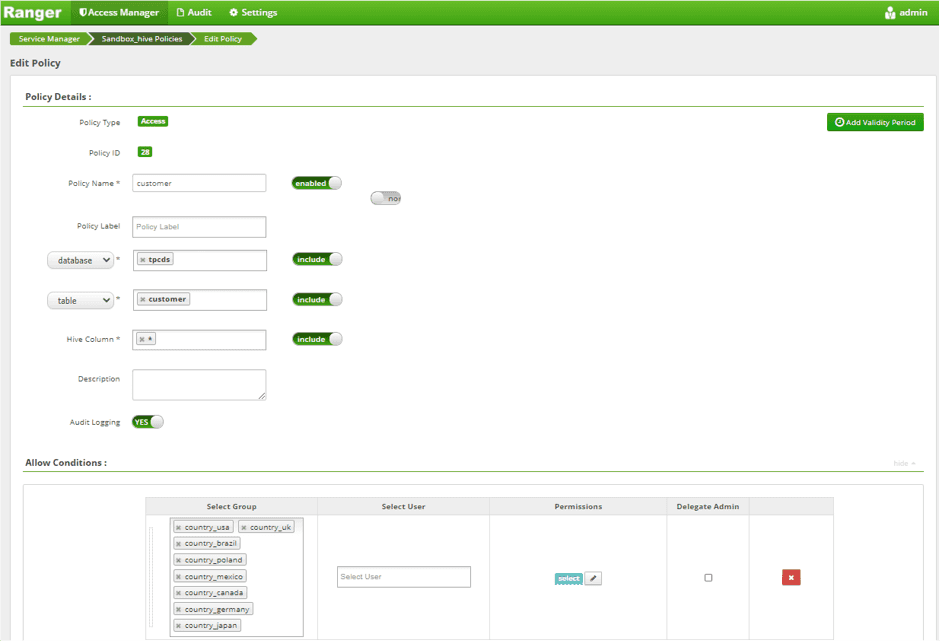
| group | access | condition |
|---|---|---|
| country-usa | select | c_birth_country = ‘USA’ |
| country-germany | select | c_birth_country = ‘Germany’ |
| country-mexico | select | c_birth_country = ‘Mexico’ |
| … + 5 | ||
| central-office | select | < no conditions > |
sr_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='UNITED STATES')
sr_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='JAPAN')
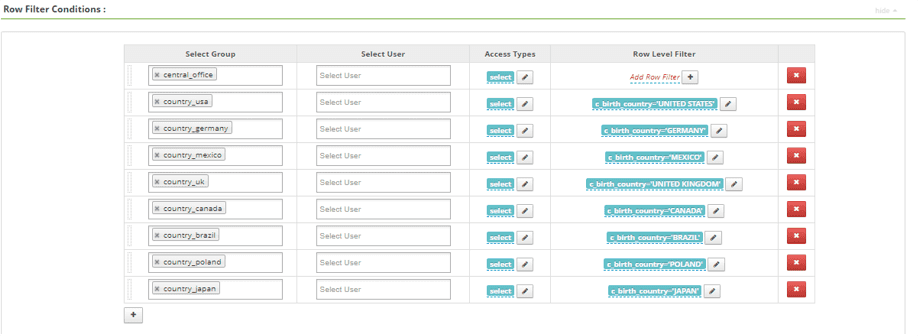
- Write the row-level policy against the store_returns and store_sales table. These two tables contain a single column. <XX_customer_sk> must be set individually for each table.
| group | access | condition |
|---|---|---|
| country-usa | select | <XX_customer_sk> in (select c_customer_sk from db.schema.customer where c_birth_country = ‘USA’) |
| … + 7 | ||
| central-office | select | < no conditions > |
sr_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='UNITED STATES')
sr_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='JAPAN')
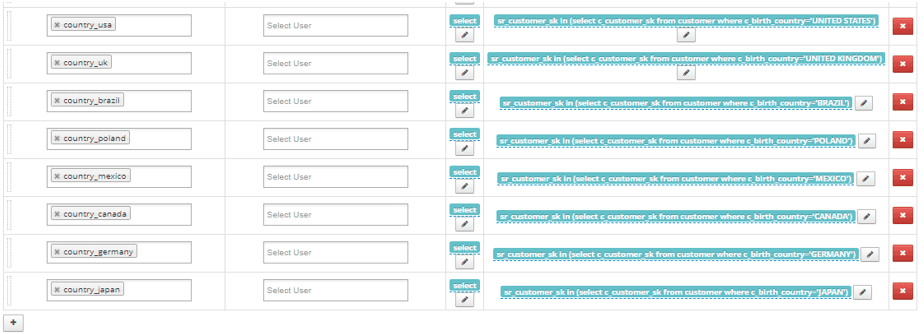
ss_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='UNITED STATES')
ss_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='JAPAN')
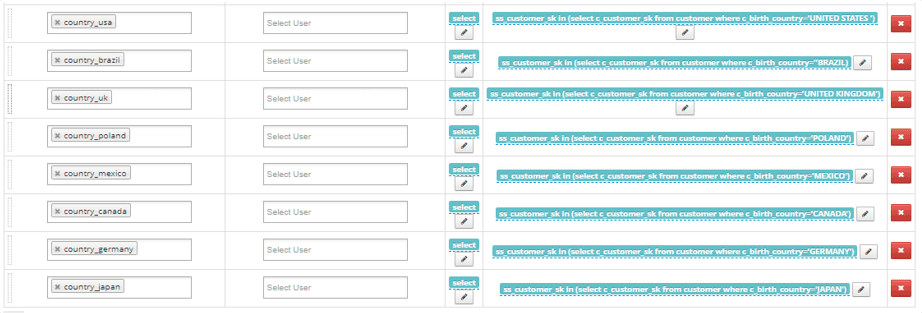
- Write the row-level policy against the remaining 4 tables. Each of these four tables contain a single column. <XX_colY_customer_sk> must be set individually for each table.
| group | access | condition |
|---|---|---|
| country-usa | select | <XX_col1_customer_sk> in (select c_customer_sk from db.schema.customer where c_birth_country = ‘USA’) AND <XX_col2_customer_sk> in (select c_customer_sk from db.schema.customer where c_birth_country = ‘USA’) |
| … + 7 | ||
| central-office | select | < no conditions > |
- Write Row Level Policy Against catalog_returns Table for each of 8 Country Groups
cr_refunded_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='UNITED STATES')
AND cr_returning_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='UNITED STATES')
cr_refunded_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='JAPAN')
AND cr_returning_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='JAPAN')
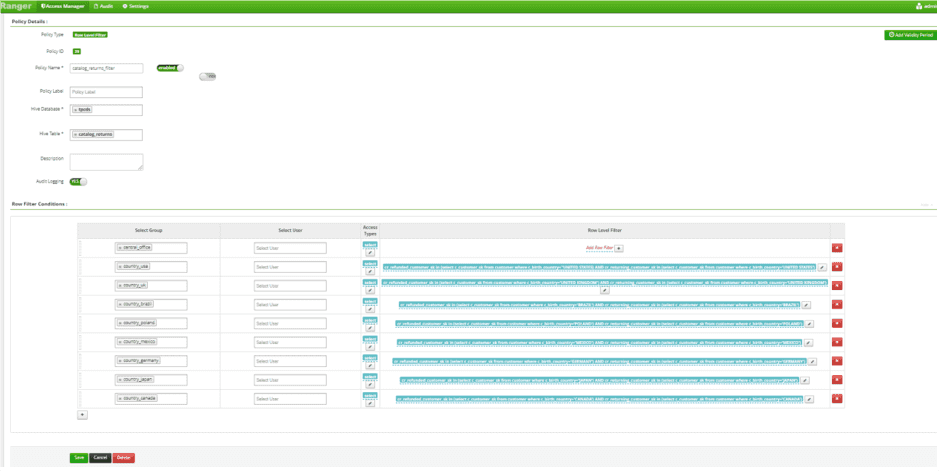
- Write Row Level Policy Against catalog_sales Table for each of 8 Country Groups
cs_bill_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='xxx')
AND cs_ship_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='xxx')
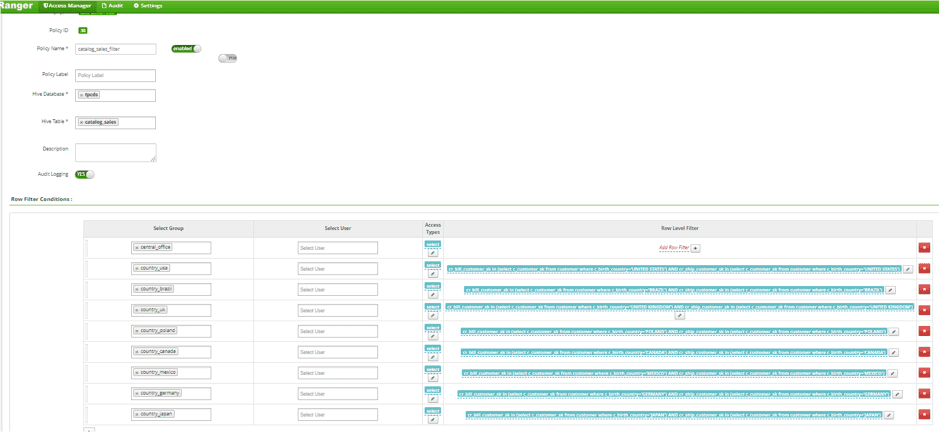
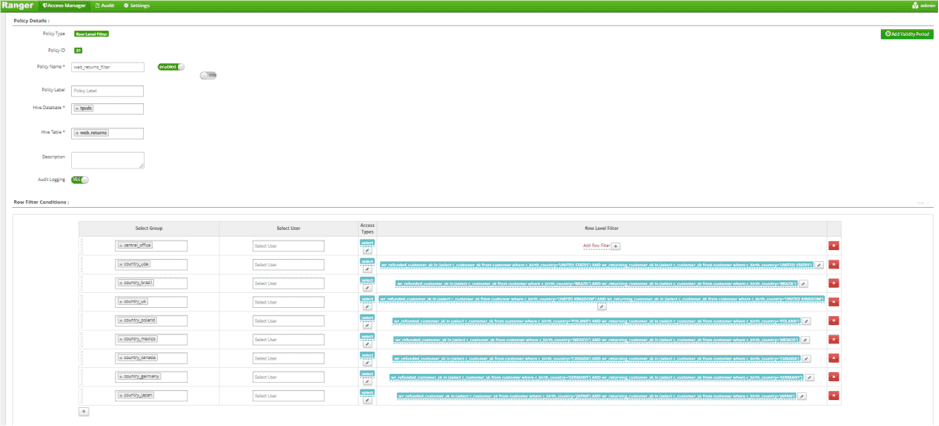
- Write Row Level Policy Against web_returns Table for each of 8 Country Groups
wr_refunded_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='xxx')
AND wr_returning_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='xxx')
- Write Row Level Policy Against web_sales Table for each of 8 Country Groups
ws_bill_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='xxx')
AND ws_ship_customer_sk in (
select
c_customer_sk
from customer
where c_birth_country='xxx')
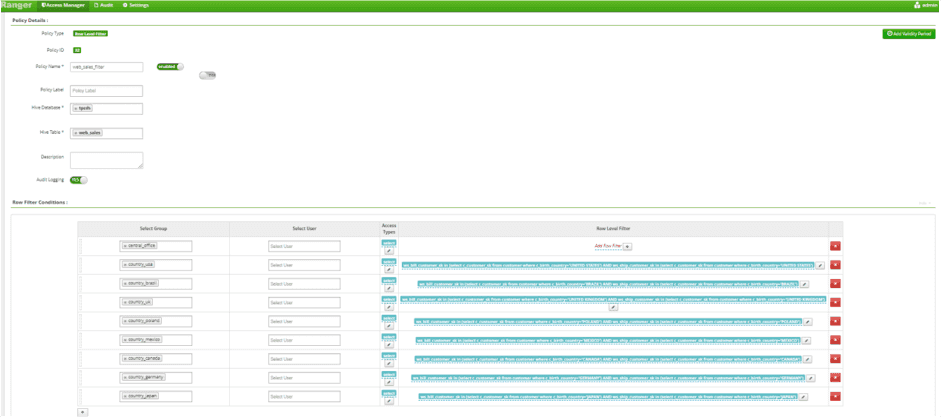
- Updated Access Policy to allow Country Groups to access catalog_returns, catalog_sales, web_returns, and web_sales Tables
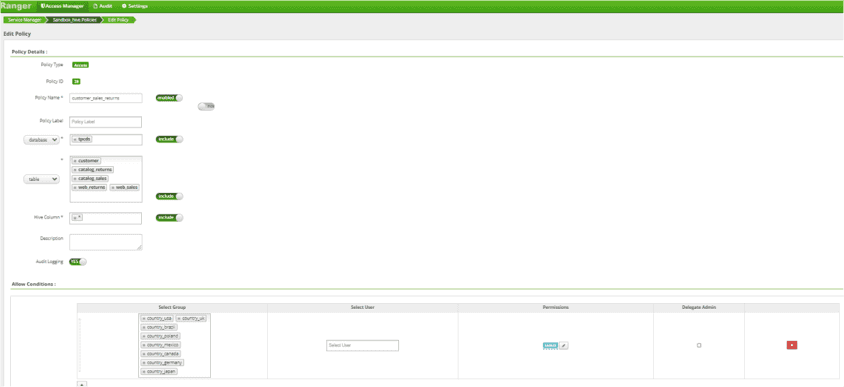
Comments:
Mismatches between the AD group name (country-mexico) and the actual value in the backing table (“MEXICO” vs. “MX” vs. “Mexico”) could cause issues.
Scenario 2f: Users on the data and analytics team should have access to all records by default
Background:
New data teams have been established in the global office, and all policies should be updated to allow these teams to access all store records and all customer records.
Data:
The data is the same as in previous scenarios.
Users:
There is a new AD group:
- AD Group: analytics
Requirements:
Users on the analytics team should have access to all records by default.
Steps in Ranger:
- Update Store Access Policy to Allow analytics Group to Access 3 Store Tables
- Update Customer/Sales/Returns Access Policy to Allow analytics Group to Access 5 Related Tables
- Update Tag Based PII Access Policy to Exclude analytics Group
- Update Tag Based EMAIL Access Policy to Exclude analytics Group
- Update Tag Based PII Masking Policy to Allow analytics Group to See Unmasked Data
- Update Tag Based EMAIL Masking Policy to Allow analytics Group to See Unmasked Data
- Update All of 8 Low Level Filter Policies to Allow analytics Group to Final Exceptions Clause
Comments:
The Ranger’s approach does not seem like a scalable solution. It requires a dozen policy rework.
Scenario 2g: Re-creating policies on derived datasets
Background:
With an analytics team in place with broad access to data, they have created dozens of derivative datasets based on the original data products. As they plan to re-expose these new tables into data products for store management, all policies need to be reapplied.
Data: The analytics team would like to expose:
- 5 tables with store level data only
- 5 tables with customer data only
- 5 tables with customer and store level data
Users:
All users/groups in previous scenarios are present.
Requirements:
Existing policies should be applied on derived datasets.
Steps in Ranger:
- For each of the 10 data sources with store data, recreate the original policies, making sure the correct column names are used.
- For each of the 10 data sources with customer data, recreate the policies, making sure that the column names used are identical.
Comment:
As a data set scales, Ranger requires new policies to be created and the complexity is increasing.
Scenario 2a - 2g: Total Counts of Policies Created/Edited, User Attributes Created/Edited, and Tag Created/Edited of each scenario
| Scenario | 2a | 2b | 2c | 2d | 2e | 2f | 2g |
|---|---|---|---|---|---|---|---|
| Policies created | 3 | 6 | 15 | ||||
| Policies edited | 1 | 3 | 5 | 4 | 14 | 2 | |
| User attributes created | 37 | 28 | 30 | 81 | 140 | 310 | |
| User attributes edited | 1 | 14 | |||||
| Tags created | |||||||
| Tags applied | 2 |
Advanced Access Controls and Privacy
Scenario 3a: Grant permission based on “AND” logic
Background:
The data team has uploaded human resources data which is considered Personal AND Business Confidential. Existing groups for “May access personal data” and “May access sensitive data” already exist.
Data:
Schema:
- employee_id
- employee_name
- start_date
- salary
Size: 10,000 records Tags: [Personal, Business Confidential]
Requirements:
Only users in both these groups should have access to the new human resources data.
Steps in Ranger:
- Ranger does not support AND logic in their policies. This will require the creation of a new role and leveraging that role in a new table policy.
Scenario 3b: Minimization Policies
Background:
To limit expensive queries that rapidly escalate compute cost in the cloud, the finance team requires a policy to limit data access to 25% of data in a table for all users as more consumers are accessing data with different tools where there is limited control of what queries are being generated.
Create a policy to enforce this for all users unless they are part of the analytics team.
Steps in Ranger:
Apache Ranger cannot limit data access per data volume usages in a table. A suggestion is to create a tool or application which will store the table in cache and capture/update the real-time data consumption rate or data usage. A plugin similar to Hive Plugin in Ranger is required to integrate with the cached data into Apache Ranger. Then a policy can be created in Apache Ranger to enforce this table access for all users per the predefined limit of captured real-time data consumption rate (e.g., 25 % of data) unless they are part of the analytics team.
Scenario 3c: De-identification Policies
Background:
The legal team has concerns about insider attacks on customer data and requires guarantees against linkage attacks, and needs to see sufficient proof you have demonstrated this. For any combination of quasi-identifiers (QI) such as c_birth_country and c_birth_year in the [customer] table, how would you mask those values using k-anonymity such that the least populated cohort is greater than 4. The k-anonymity of a data source is defined as the number of records within the least populated cohort, which means that the QIs of any single record cannot be distinguished from at least k other records. In this way, a record with QIs cannot be uniquely associated with any one individual in a data source, provided k is greater than 1.
Steps in Ranger:
Masking Policies in Apache Ranger do not support calculating and using k-anonymity for some value of k. I would suggest to create a User Defined Function (UDF) in Hive database to calculate the k-anonymity on the c_birth_country and c_birth_year columns in the customer table. Then a masking policy can be created against the customer table. We can apply the k-anonymity value by invoking the UDF function in Policy Conditions on the masking policy to provide guarantees against linkage attacks.
Scenario 3d: Policies with Purpose Restrictions
Background:
Customer data can only be used by the analytics team for the purpose of fraud detection for [orders] shipped to less common countries. The policy requires that purpose must be acknowledged by the user prior to accessing data.
Steps in Ranger:
Apache Ranger Resource Based Access Control Policies cannot support any acknowledgement function prior accessing data. I would suggest to create a User Defined Function (UDF) in Hive database to redirect users to a Web site or a pop up message box to acknowledge the accessing the data, and allow their access to the table when the acknowledgement is made. A Hive View with the embedded UDF function over the Customer table in the Hive database is required. When a data access policy is created, the policy will be applied on the Hive View and the data access will only be granted to the analytics team. When analytics team members access the Hive view, the view will redirect the members to a Web site or a pop up message box for the acknowledgement prior to access the data.
The future of data access management
Apache Ranger played a key role in Hadoop adoption across various industries. Companies used Ranger to protect data assets, ensure compliance. As showcased in the above scenarios, Ranger could meet some of the basic requirements and other scenarios required unnecessary repetitions and overengineering, or were not possible to implement altogether.
Yet, the world and technology does not stand still:
- Hadoop, once a desired piece of technology, became a hot potato that companies try to get rid of
- The rise of Cloud Data Platforms and Lakehouse concept combines the best of data warehouses and data lakes into a single platform
- Cloud, managed PaaS and SaaS offerings win over self-hosted infrastructure
- The shift from centralized to distributed data platform thinking introduces enormous data governance challenges
These trends put a lot of pressure on data security, privacy, access management. Apache Ranger was a powerful tool for Hadoop, yet over complex access policy management makes me question its place in the modern data stack.
Related Posts
Other projects